SQL Abfrage (Werkzeuge)
SQL Abfrage ermöglicht Benutzern SQL (Structured Query Language) zu verwenden, um Daten in einer Datenbank zu bearbeiten, zu aktualisieren, zu speichern, zu löschen und zu abfragen.
Bitte legen Sie Views und Tabellen nie manuell im SQL Query and sondern immer über den Knopf "View erzeugen" in der Datenstrukturanzeige.
Um sicherzustellen, dass die Änderungen an Views oder Tabellen, die mit anderen Tools vorgenommen werden, im AppBuilder sichtbar sind, muss die Datenbankverbindung manuell aktualisiert werden. Auf diese Weise können die Änderungen angezeigt und verwendet werden.
Das SQL Abfrage Werkzeug wird über die Datenbankverbindung gestartet, zuerst die Datenbankverbindung öffnen und darüber kommt man zur SQL Abfrage für diese Datenbankverbindung:
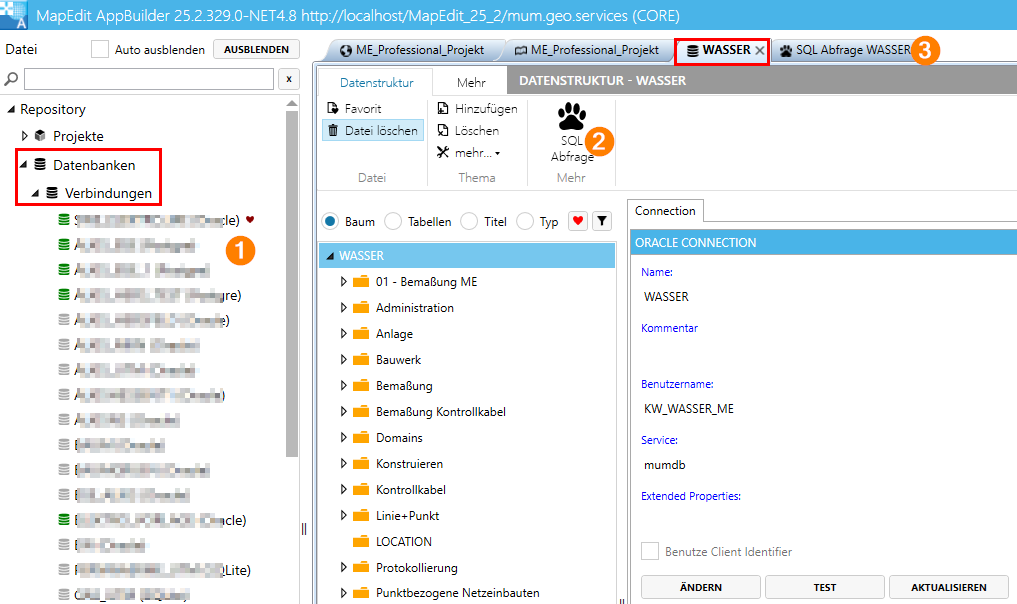
Die SQL Abfrage Oberfläche
Das SQL Abfrage Werkzeug hat mittlerweile 2 Register:
Ein und Ausgabe Register (Input/Output)
Hiermit können sie mehrere SQL Ausdrücke gleichzeitig verwalten und zwischen diesen hin und her springen.
Wenn ein SQL ausgeführt wird, dann erscheint das Ergebnis in dem gerade aktiven "Output" Register. Hiermit kann man Ergebnisse von SQLs in einem eigenen Register ablegen und später jederzeit anzeigen, ohne durch lange Seiten scrollen zu müssen.
Tabellen Anzeige
Hier werden alle Tabellen und Views der Datenbank in verschiedenen Ansichten angezeigt.
Bei Eingabe der ersten Zeichen im Filter werden alle Tabellen die den Wortteil enthalten angezeigt.
Hier steht ein Rechte Maus Kontext Menu zur Verfügung.
| Menu | Beschreibung |
|---|---|
| Run 'Select * from' | Führt ein 'Select * from' der gewählten Tabelle aus. |
| Write 'Select * from' | Schreibt ein 'Select * from' in den Eingabebereich ohne das SQL auszuführen |
| Run 'Select * from' first 100 rows only | Führt ein Select der ersten 100 Datensätze aus |
| Write 'Select * from' first 100 rows only | Schreibt einen Select der ersten 100 Datensätze in den Eingabe Bereich |
| Grid/Table Edit | Öffnet einen Dialog in dem die Datensätze bearbeitet werden können. |
Spalten Anzeige
Hier werden die Spalten der in der Tabellen Anzeige ausgewählten Tabelle angezeigt.
Hier steht ein Rechte Maus Kontext Menu zur Verfügung.
Wählen Sie eine oder mehrere Spalten und führen Sie das Menu "Select ? from"
aus um ein Select SQL mit den Namen aller gewählten Spalten zu erzeugen.
SQL Ausführen Knöpfe
![]()
Der erste blaue Knopf führt alle SQLs die im Eingabebereich stehen aus.
Der zweite blaue Knopf führt den SQL aus der an der aktuellen Position des Eingabe Cursors steht. Dies kann nützlich sein wenn man mehrere SQLs die durch ";" getrennt sind im Eingabe Bereich stehen hat und nur einen bestimmten SQL ausführen möchte.
Die Schwarzen Knöpfe machen das selbe wie die blauen Knöpfe nur das jeweils vorab der Ausgabe Bereich geleert wird.
Optionen
![]()
Option "Geometry Format"
Mit "Geometry Format" können Sie bestimmen, wie Geometrien dargestellt werden sollen. Standardmäßig ist "short (kurz)" eingestellt, was eine abgekürzte Darstellung der Geometrie bedeutet. Bei Linien und Flächen werden nur die Anfangs- und Endpunkte angezeigt, statt aller Stützpunkte.
Außerdem wird in der Darstellung auf zwei Nachkommastellen gerundet.
Wenn Stützpunkte vorhanden sind wird ein ".." angezeigt.
Beispiel Linie mit Stützpunkten
LineString(665971.73,4003145.04 .. 665971.73,4003145.04)
Beispiel Linie die nur einen Anfangs und Endpunkt hat ohne weiteren Stützpunkte
LineString(665971.73,4003145.04 665971.73,4003145.04)
Bedenken Sie das eine Linien oder Flächen Geometrie tausende von Stützpunkten haben könnte und das Ausgeben all dieser, lange dauern würde und den Editor extrem langsam machen würde. In den meisten Fälle benötigt der Anwender diese Informationen auch nicht. Wenn die vollen Informationen benötigt werden kann das Format umgeschaltet werden.
Option "NULL"
Standardmäßig werden NULL Werte als Leerzeichen angezeigt. Wenn Sie explizit NULL Werte anzeigen wollen können sie diesen Schalter einschalten. NULL Werte werden dann als "(null)" ausgegeben.
Option "Quotes"
Setzt alle Textwerte in einfache Anführungszeichen. Dadurch können Leerzeichen besser erkannt werden.
Option "Plain"
Erzeugt eine reinen Ausgabe ohne Spaltenköpfe etc. Alle Spaltenwerte werden durch Komma separiert. Zeilenumbrüche (CR+LF) werden bei dieser Option in der Ausgabe beibehalten.
Option "Wrap"
Bricht lange Ausgaben in mehrere Zeilen um.
Option "Auto complete"
Schaltet die Automatische Tabellen und Spaltennamen Komplettierung ein/aus.
Register "Statement Wizzard"
Das Register zeigt ihnen die Spalten aller im SQL beteiligten Tabellen an. Auf der linken Seite sehen Sie alle Tabellen die eine direkte Relation zu den den im SQL angegebenen Tabellen haben und somit eine hohe Wahrscheinlichkeit besteht das Sie diese im SQL verwenden wollen.
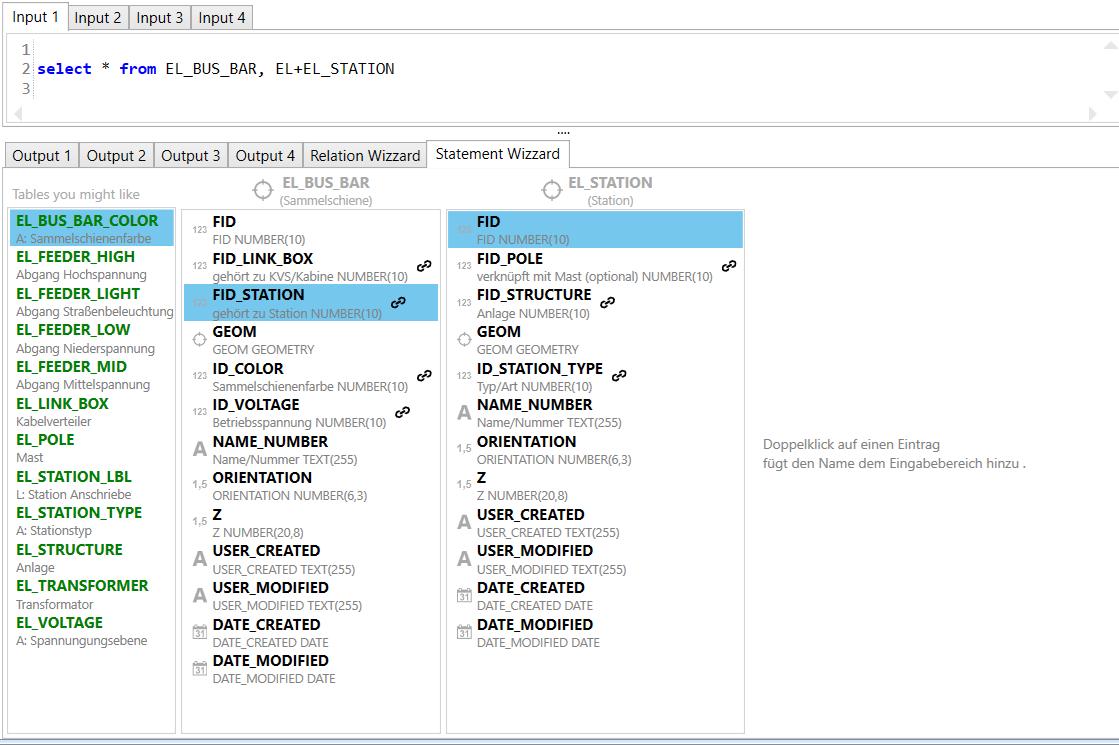
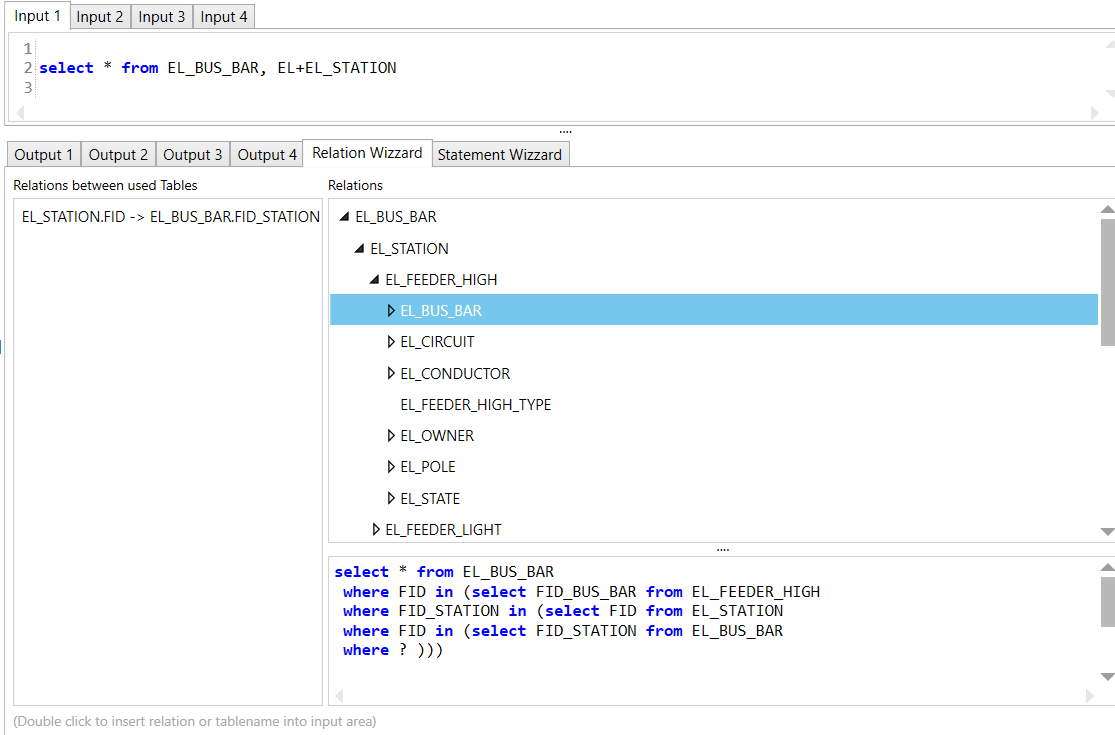
Register "Relation Wizzard"
Der Relationen Wizzard zeigt Relationen der im SQL angegebenen Tabellen an. Durch Doppelklick auf ein Relation in der linken List kann ein Relations Ausdruck in den Eingabebereich eingefügt werden.
Auf der Rechten Seite sehen Sie einen Relationsbaum. Dieser zeigt die Relationen und Kind Relationen der Tabellen an.
Im unteren Bereich sehen sie wie ein SQL Vorlage aussehen muss die die Relation abbildet. Beachten Sie das hier jeweils zwei SQLs stehen. Scrollen Sie nach unten um den zweiten SQL zu sehen. Der zweite SQL gibt die Relation in Gegenrichtung an.
Erzeugen von FIDs
Die MapEdit Datenstruktur benutzt die Datenbank Sequenz ME_NEXT_FID für die Erzeugung einer Datenbankweiten eindeutigen FID. D.h. jede FID gibt es je Datenbankuser nur einmal. D.h. die FID 117 kann es nicht in zwei Tabellen geben.
Wenn Sie Datensätze mittels INSERT SQL oder Fremdtools in die Datenbank einfügen wollen, dann können Sie die FID automatisch erzeugen lassen in dem Sie für die FID den Wert 0 angeben. Datenbank Trigger wandeln den Wert 0 dann mittels der Sequence in eine gültige FID um.
Bei Oracle und Postgres kann auch NULL statt 0 für die FID angegeben werden. Bzw die FID beim INSERT weg gelassen werden.
Bei SQLite und Postgres muss aber immer zwingen der Wert 0 angegeben werden!
Commit und Rollback
Rollback und Commit/Transactions gibt es in MapEdit AppBuilder SQL Abfragen nicht. Alle Abfragen werden sofort committed. Man kann die zwei Befehle Commit oder Rollback absetzen, bewirken tun sie jedoch nichts.
Im Gegensatz zu AutoCAD Map3D benötigt MuM MapEdit keinen Oracle oder Datenbank Client auf dem lokalen Client PC und ist statuslos, da es technisch eine Web Applikation ist. Ein SQL-Befehl wird abgesetzt und dann "gepoolt", d.h. die nächste Aktion die kommt, egal von welchem Client, benutzt eine "offene" Verbindung. Wird diese Verbindung lange nicht benutzt, wird diese geschlossen.
Einen SQL als Block ausführen
Wenn Sie mehrere SQL Befehle durch ';' getrennt eingeben, werden alle durch ';' abgeschlossene Befehle als ein SQL Befehl ausgeführt.
Dies kann beim Anlegen von Triggern oder Stored Procedures Probleme schaffe.
Statt dem ';' Zeichen kann deswegen Optional der BEGIN/END SQL Kommentar verwendet werden um den Beginn und das Ende des Befehls festzulegen.
Beispiel:
--BEGIN SQL
CREATE TRIGGER test_trg
INSTEAD OF UPDATE
ON strassen
FOR EACH ROW
BEGIN
UPDATE dept
SET location=:new.location
WHERE dept_name=:old.dept_name;
END;
--END SQL
Beachten Sie das BEGIN SQL und END SQL in Großbuchstaben geschrieben werden muss. Davor muss ein je ein -- stehen. Danach und davor dürfen keine Leerzeichen stehen. Jeder der beiden Befehle muss in einer eigenen Zeile stehen.
Variablen in SQLs verwenden
Sie können eigene Variablen definieren und innerhalb der SQL Befehle verwenden. Der Inhalt der Variablen wird dann zur Laufzeit ersetzt.
Setzen Sie eine Variable mit dem "VARIABLE SET" Befehl.
Beispiel:
VARIABLE SET ~TableName~ =BAUM;
select * from ~TableName~;
Der Befehle ersetzt TableName durch den Wert BAUM
und erzeugt dadurch den SQL
select * from BAUM;
Variablen Namen müssen immer mit einem '~' Zeichen beginnen und enden. Variablen Namen sind case sensitive, d.h. Gross/Kleinschreibung muss eingehalten werden.
Zum anzeigen des aktuellen Inhaltes einer Variable verwenden sie:
VARIABLE SHOW ~NAME~
Zum entfernen einer Variable verwenden Sie:
VARIABLE REMOVE ~NAME~
Einen C# String erzeugen
Dieser Befehl ist für Entwickler nützlich.
Wenn man vor einen SELECT Befehl "C#" schreibt, dann macht einem das Programm daraus einen C# String.
Beispiel:
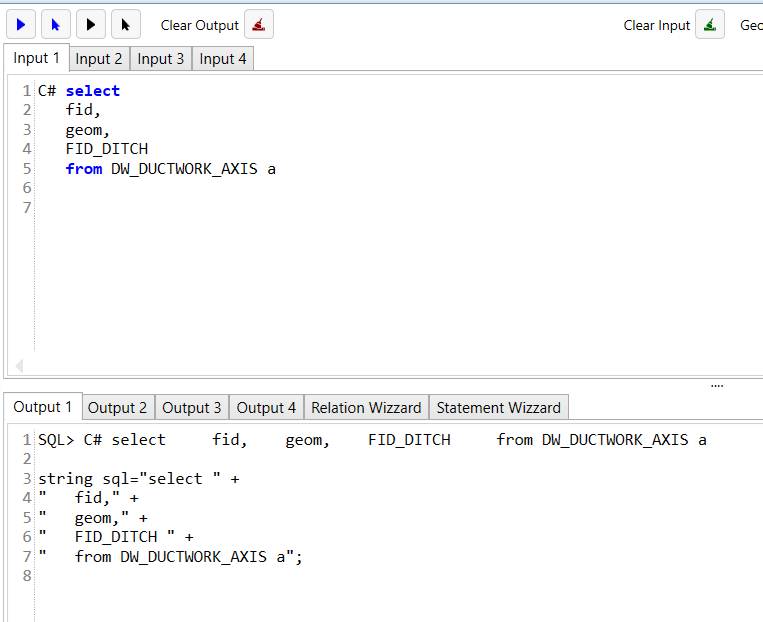
Einen SQL formatieren
Mit der Funktion FORMATSQL kann man ein SQL Formatieren lassen.
Bei der Formatierung werden die Spalten und where Bedingungen etc in jeweils eine Zeile geschrieben.
Beispiel:
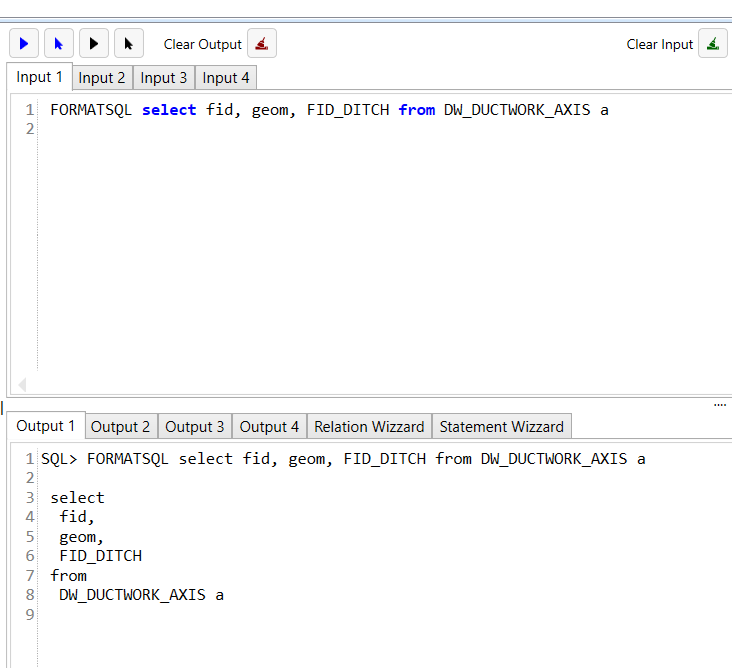
Ausgabe leeren
Mit dem Befehle CLS und CLEAR kann das aktive Ausgabe Fenster geleert werden.
SQL Ergebnis seitenweise ausgeben
Wenn man einen Select SQL im SQLQuery ausführt wird einem das Ergebnis standardmäßig als Tabelle dargestellt. Das kann manchmal unpraktisch sein.
Deswegen gibt es die Möglichkeit Datensätze "Seitenweise" anzuzeigen. D.h. alle Spalten / Wertepaare eines Datensatzes werden untereinander statt nebeneinander dargestellt.
Dies erreicht man wenn vor den SELECT das wort PAGE geschrieben wird.
Beispiel:
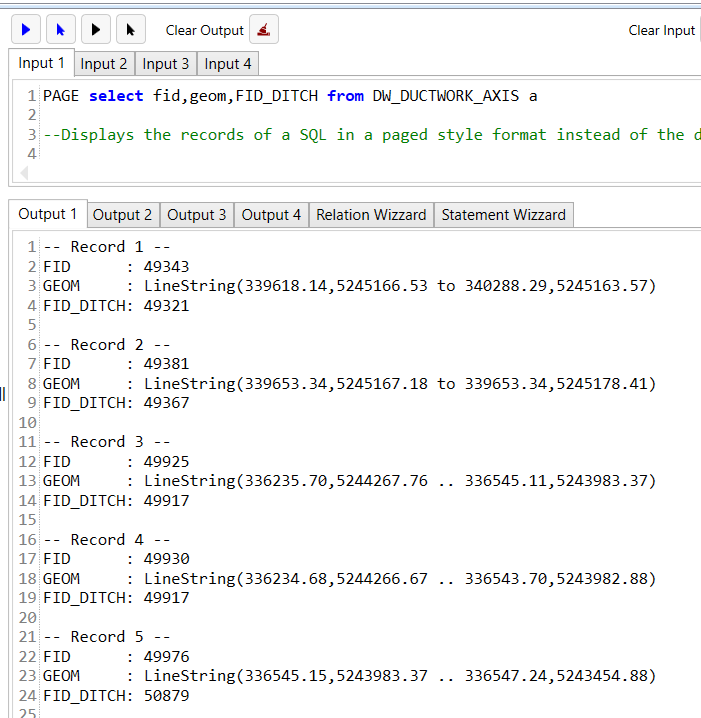
repeatforBefehl
Beschreibung
Die Syntax ist gleich wie im SQLSheet
--Add a Column to all Tables
repeat
alter table $table_name add(nase number(1))
FOR
select table_name from user_tables;
Es darf nur ein SQL Ausdruck nach dem repeat stehen. Mehrere Ausdrücke mit ";" getrennt sind nicht erlaubt.
Beispiele:
Anzahl aller Datensätze aller Tabellen
repeat
select count(*) from $table_name
FOR
select table_name from user_tables;
Allen Domain Tabellen eine Spalte hinzufügen
repeat
alter table $TABLE_NAME add VALUE_EN varchar2(255)
FOR
select TABLE_NAME from ME_TABLE where IS_DOMAIN=1
Der Ausdruck nach dem REPEAT wird solange wiederholt wie es Datensätze in dem select nach dem FOR Ausdruck gibt.
Im REPEAT SQL werden alle Ausdrücke die ein "$" voranstehen haben durch den Wert des Datensatzes des gleichen Spaltennamens des FOR Ausdruckes ersetzt.
Es wird also das hier ausgefuehrt.
select TABLE_NAME from ME_TABLE where IS_DOMAIN=1
ergibt:
TABLE_NAME
DUCK_TYPE_TBD
WATERPIPE_TYPE_TBD
COLOR_NAME_TBD
nun wird der SQL im REPEAT Befehlt 3 mal (für jedes der Ergebnisse) ausgeführt wobei der $ Wert durch den Wert des Datensatzes ersetzt wird.
also
alter table DUCK_TYPE_TBD add VALUE_EN varchar2(255)
alter table WATERPIPE_TYPE_TBD add VALUE_EN varchar2(255)
alter table COLOR_NAME_TBD add VALUE_EN varchar2(255)
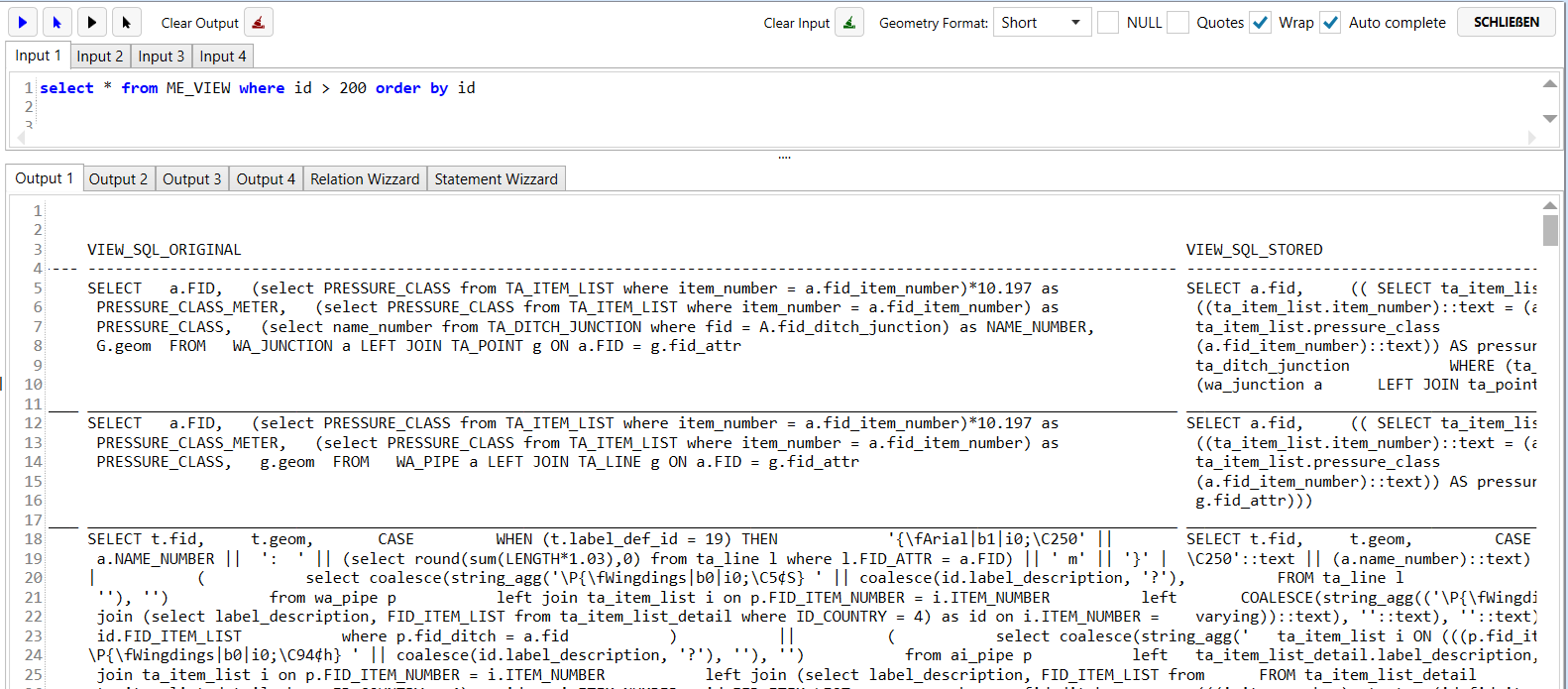
Wrap / Umbruch Funktion
Wrap column data longer than 120 character
Wenn man Wrap (Umbruch) einschaltet, dann wird, wenn der Wert einer Spalte länger als 120 Zeichen ist, umgebrochen.
Per default ist diese Funktion eingeschaltet. Das Programm merkt sich jedoch den letzten Zustand wenn dies ausgeschaltet wird. Zwischen Zeilen die lange Werte haben wird ausserdem eine Linie gezeichnet.
Wenn man lange Werte hat wird die Darstellung oft sehr unübersichtlich.
Beispiel mit Wrap aus.
Beispiel mit Wrap ein.
 .
.
Datenbank Schema reparieren (CleanSchema)
Ab Version 25.2.272
Mit dem Befehl CleanSchema können bei Datenbanken mit MapEdit Datenstrukturen die ME System Tabellen aufgeräumt werden.
D.h. Nicht mehr vorhandene Tabellen und Views werden aus den ME Tabellen ME_TABLE und ME_VIEW entfernt. Desweiteren werden Labeldefinition auf nicht mehr vorhandenen Tabellen entfernt.
Dieser Befehl entspricht 1:1 den beiden Datenbankwartungsbefehlen
- Prüfe System Tabellen
- Prüft Label Definitionen
Details siehe:
https://help.mapedit.de/docs/next/dokumentation/MapEdit-AppBuilder/database-connections/maintenace
Datenbank klonen/kopieren
Mit dem Befehl CloneDatabase können Sie eine Postgres Datenbank kopieren.
Es spielt bei diesem Befehl keine Rolle mit welcher Datenbankverbindung das SQL Query Werkzeug aktuell verbunden ist.
Beispiel:
CloneDatabase TargetDatabase=am0002_plan_1, SourceDatabase=masterplan_template, SuperConnection='POSTGRE:UserId=postgres;Password=manager;Server=localhost;Port=5432;';
TargetDatabase = Name der neu anzulegenden Datenbank.
SourceDatabase = Name der Datenbank die kopiert werden soll.
SuperConnection = Datenbankverbindung zu einem Super User z.B. der user "postgres".
Der Super User muss Rechte haben neue Datenbanken anzulegen.
Beachten Sie dass die Namen die Namen der Datenbank sind und nicht die Namen der Datenbankverbindung
Der Befehl kann mit dem "Repeat" Befehl kombiniert werden um mehrere Datenbanken im Batch an zu legen.
Der Select im FOR Abschnitt geht auf die aktuelle Datenbank des SQL Abfrage Tools
Beispiel:
REPEAT
CloneDatabase TargetDatabase=$dbname, SourceDatabase=masterplan_template, SuperConnection='POSTGRE:UserId=postgres;Password=manager;Server=localhost;Port=5432;'
FOR select lower(dbname) as dbname from DATABASENAMES;
Datenbank löschen
Mit dem Befehl DropDatabase können Sie eine Postgres oder Oracle Datenbank löschen.
Es spielt bei diesem Befehl keine Rolle mit welcher Datenbankverbindung das SQL Query Werkzeug aktuell verbunden ist.
Beispiel:
DropDatabase Database=am0002_plan_1, SuperConnection='POSTGRE:UserId=postgres;Password=manager;Server=localhost;Port=5432;'
Database = Name der zu löschenden Datenbank.
Dass dies der wirkliche Name der Datenbank ist und nicht der Name der Datenbankverbindung
SuperConnection = Datenbankverbindung zu einem Super User z.B. der user "postgres".
Der Super User muss rechte haben eine Datenbanken zu löschen.
Der Befehl kann mit dem "Repeat" Befehl kombiniert werden um mehrere Datenbanken im Batch anzulegen.
Beachten Sie das der Select im FOR Abschnitt auf die aktuelle Datenbank des SQL Abfrage Tools geht.
Beispiel:
REPEAT
DropDatabase Database=$dbname, SuperConnection='POSTGRE:UserId=postgres;Password=manager;Server=localhost;Port=5432;'
FOR select lower(dbname) as dbname from DATABASENAMES;
Featureklassen Tabelle anlegen
Mit dem Befehl CREATEFEATURECLASS können Sie eine neue Featureklassen Tabelle anlegen. Anders als CREATE TABLE registriert dieser Befehl die Tabelle und legt alle Standard Spalten an. Mit der Option "CopyAttributesFrom" können auch die Spalten einer anderen Tabelle übernommen werden. Mit TargetConnection kann z.B. die Tabelle in einer anderen Datenbank angelegt werden.
Dieser Befehl kann nur in MapEdit Datenstrukturen angewendet werden.
Beispiele:
CREATEFEATURECLASS Name="WEG", Type="LineString";
CREATEFEATURECLASS Name="BAUM", Type="Point", Caption="Mein Baum", Topic="Gruenflaechen";
CREATEFEATURECLASS Name="SEE", Type="Polygon", Topic = "Gruenflaechen\Andere";
CREATEFEATURECLASS Name="BUSCH", Type="Point", CopyAttributesFrom="GEWAECHS";
| Parameter | Information |
|---|---|
| Name | Name der Tabelle |
| Caption | (optional) Beschriftung der Tabelle |
| Type | (optional) Feature Typ (siehe unten) |
| Topic | (optional) Topic. Verwenden sie das "" Zeichen wenn sie Unter Themen anlegen wollen. |
| SourceConnection | (optional) Quell Datenbank für CopyAttributesFrom (Leer wenn die aktuelle Datenbankverbindung genutzt werden soll) |
| TargetConnection | (optional) Datenbankverbindung in der die Tabelle angelegt werden soll wenn diese nicht die gleiche wie die aktuelle Datenbankverbindung ist. |
| CopyAttributesFrom | (optional) Name der Tabelle in der Source Connection von der alle Spaltendefinitionen kopiert werden sollen. |
Wird Topic weggelassen wird das erste vorhandene Topic verwendet. Wird Type weggelassen wird als Type = "Attribute" verwendet.
Mögliche Werte für Type:
- Point
- LineString
- Polygon
- Attribute
- Domain (Kennungslisten)
- Label
- Centroid
- Collection
- CompoundLineString
- CompoundPolygon
- Dimension
Featureklassen Tabelle registrieren
Registriert eine Tabelle in ME_TABLE. Der Befehl ist vergleichbar mit "CREATEFEATURECLASS" nur das hier die Tabelle bereits vorhanden ist.
Dieser Befehl kann nur in MapEdit Datenstrukturen angewendet werden.
Beispiele:
REGISTERFEATURECLASS Name="WEG", Type="LineString";
REGISTERFEATURECLASS Name="BAUM", Type="Point", Caption="Mein Baum", Topic="Gruenflaechen";
REGISTERFEATURECLASS Name="SEE", Type="Polygon", Topic = "Gruenflaechen\Andere";
Views Registrieren
Diese Funktion steht nur für MapEdit Datenmodelle zur Verfügung
Registriert Views in der Tabelle ME_VIEW und ME_TABLE.
Die ist z.B. bei umfangreichen Migrationen nützlich wo sehr sehr viele Views angelegt werden und das arbeiten mit der Benutzeroberfläche sehr aufwendig wird.
Sie sollten dies ausführen wenn Sie Views via SQL anlegen müssen.
Es ist ratsam Views und Tabellen immer via der MapEdit AppBuilder Benutzeroberfläche anzulegen da hierbei das Füllen von Systemtabellen automatisch geschieht.
Vor dem ausführen von "RegisterView" im SQL Tool muss in der gleichen Sitzung das "Create View" oder "Create or replace View" des Views der registriert werden soll ausgeführt werden. Die Funktion "RegisterView" liest daraus dann den erzeugten View SQL und speichert den Original SQL und den SQL der Datenbank in der Tabelle ME_VIEW ab.
Beispiel:
Drop View V_FIRE_STATION;
Create View V_FIRE_STATION as SELECT t.fid,t.geom,t.label_text
FROM FIRE_STATION_LBL t,FIRE_STATION a WHERE t.fid_parent=a.fid;
RegisterView Name=V_FIRE_STATION,
ViewType=LABEL, ContentType=LABEL,AttributeTable=FIRE_STATION,
GeometryTable=FIRE_STATION_LBL;
Wenn sie den View nicht neu erzeugen wollen weil dieser eine lange Laufzeit hat können Sie wahlweise auch den Befehl "DefineView" ausführen.
DefineView V_FIRE_STATION as SELECT t.fid,t.geom,t.label_text
FROM FIRE_STATION_LBL t,FIRE_STATION a WHERE t.fid_parent=a.fid;
RegisterView Name=V_FIRE_STATION, ViewType=LABEL,
ContentType=LABEL,AttributeTable=FIRE_STATION,
GeometryTable=FIRE_STATION_LBL;
Mögliche Werte für "ViewType"
- Unknown
- Utility
- Label
- Representation
Mögliche Werte für "ContentType"
- Point
- LineString
- Polygon
- Attribute
- Domain (Kennungslisten)
- Label
- Centroid
- Collection
- CompoundLineString
- CompoundPolygon
- Dimension
Wenn man bei Postgres einen View erzeugt dann speichert Postgres nicht den vom Anwender eingegeben View ab sondern Postgres ändert den View ab und fügt Castings und andere Sachen dem View hinzu. Deswegen speichern wir in der Tabelle ME_VIEW unter VIEW_SQL_ORIGINAL den vom Anwender eingegebenen View ab. Die Funktion Register View macht dies für Sie wenn Sie Views nicht via Benutzeroberfläche sondern händisch via SQL machen wollen.
Weitere Informationen finden Sie auch hier:
https://help.mapedit.de/docs/dokumentation/MapEdit-AppBuilder/database-connections/structure/views#postgres-und-views
Wenn der Befehl nicht funktioniert dann stellen Sie sicher das mindestens der Teil vor dem SELECT in einer Zeile steht und zwischen den Wörtern jeweils ein Leerzeichen steht und keine Zeilen Umbrüche oder Tabs zwischen allen Wörtern die vor dem Ausdruck SELECT stehen vorkommen. Korrekte Beispiele: "Create View IHRVIEW as SELECT " "Create or Replace View IHRVIEW as SELECT " "DefineView V_FIRE_STATION as SELECT "
Datensätze von einer Datenbank in andere Datenbank kopieren
Mit dem Befehl "datatransfer" können Datensätze von einer Datenbank in eine andere kopiert werden oder auch SQL Befehle auf mehrere Datenbanken nacheinander im Batch angewendet werden. Der Befehl hat mehrere Unterbefehle.
Es spielt bei diesem Befehl keine Rolle mit welcher Datenbankverbindung das SQL Query Werkzeug aktuell verbunden ist.
Datensätze können hierbei auch zwischen Datenbanken verschiedener Datenbank System kopiert werden.
Mögliche Beispiele:
- von einer SQLite Datenbank in eine Postgres Datenbank.
- von einer SQLite Datenbank in eine Oracle Datenbank.
- von einer Postgre Datenbank in eine Oracle Datenbank.
- von einer Oracle Datenbank in eine Oracle Datenbank.
- jede beliebige andere Kombination von SQLite, Oracle und Postgres
Beachten Sie dass wenn die Quell und Ziel Datenbank vom gleichen Datenbank System sind und vom Typ Oracle oder Postgres sind, dass ein direktes kopieren mittels eines Superusers wesentlich schneller ist als das Nutzen von "datatransfer".
Das folgende Beispiel kopiert die Datensätze der Tabellen AT_BAUM und AT_LAND der SQLite Datenbank "gruen.sqlite" in die Tabellen BAUM und LAND der Postgres Datenbank "stuttgart_gruen" Außerdem wird in der Quelldatenbank ein Korrektur SQL ausgeführt.
datatransfer StartNewLog;
datatransfer Clear;
datatransfer prepare execute sql in source using update ME_FILE set TABLE_NAME_PARENT='NULL' where TABLE_NAME_PARENT is null;
datatransfer prepare copy data to table BAUM using select * from AT_BAUM where baumtyp=17;
datatransfer prepare copy data to table LAND using select * from AT_LAND;
datatransfer execute with SourceConnection='SQLITE:Filename=C:\Transfer\gruen.sqlite', TargetConnection='POSTGRE:UserId=postgres;Password=manager;Database=stuttgart_gruen;Server=localhost;Port=5432;';
datatransfer ShowLog;
Erklärung der einzelnen Schritte:
datatransfer StartNewLog;
Dieser Befehl erzwingt dass eine neue Log und Error Datei im Verzeichnis
"C:\Users\IhrUser\Documents\MapEdit\DataTransfer" angelegt wird.
Wird dieser Befehl ausgelassen dann wird die zuletzt in der Sitzung verwendete Log Datei verwendet.
Das System legt hierbei zwei Dateien an. Eine Datei mit Namen *.log.txt in der alle Kopiervorgänge protokolliert werden und eine Datei mit dem Namen *.error.txt in der alle Fehler protokolliert werden.
datatransfer Clear;
Dieser Befehl sorgt dafür das alle "datatransfer prepare" Befehle aus dem Befehlsspeicher entfernt werden.
datatransfer prepare execute sql in source using update ME_FILE set TABLE_NAME_PARENT='NULL' where TABLE_NAME_PARENT is null;
Definiert das in der Quelldatenbank (source) ein SQL (z.B. ein Update, Delete, Insert etc) ausgeführt wird. Damit können Daten bereinigt, eingefügt oder gelöscht werden.
Wird hier ein SELECT Statement angegeben, dann wird das Ergebnis des Select in die Fehlerdatei ausgegeben. Dies kann zum Beispiel für Prüfungen verwendet werden. Beachten Sie dass eine Ausgabe nur erfolgt wenn ein nicht NULL Wert vorhanden ist.
Das folgende Beispiel prüft ob die Sequence 'me_next_fid' vorhanden ist und gibt wenn nicht, wird eine Meldung in die Fehlerdatei ausgegeben.
datatransfer prepare execute sql in source using SELECT case count(*) when 0 THEN 'Sequence me_next_fid is missing' end case FROM information_schema.sequences where sequence_name ='me_next_fid';
Achten Sie darauf das alle Befehle exakt so geschrieben sind wie beschrieben
z.B. "datatransfer prepare copy data to table"
mit jeweils nur einem Leerzeichen zwischen allen Wörtern!!
Dieser Befehl führt noch kein SQL aus sondern definiert nur was später beim Ausführen des Befehls "datatransfer execute" ausgeführt werden soll.
Wenn ein SQL in der Zieldatenbank (target) ausgeführt werden soll dann statt "source" das wort "target" verwenden.
datatransfer prepare copy data to table ZIEL_TABELLE using Select Befehl der die Daten der Quell Tabelle holt.
Dieser Befehl definiert welche Datensätze, welcher Quelltabelle in welche Zieltabelle kopiert werden sollen.
Es muss hierbei sicher gestellt werden das die angegebene Zieltabelle auch die Spalten des Quell Selects enthält.
Dieser Befehl führt noch kein kopieren aus sondern definiert nur was später beim ausführen des Befehls "datatransfer execute" alles kopiert werden soll.
Achten Sie darauf das der Befehl exakt so geschrieben ist
"datatransfer prepare copy data to table"
mit jeweils nur einem Leerzeichen zwischen allen Wörtern!
Verwenden Sie keine ORDER BY Statements im SQL!
datatransfer execute with SourceConnection=Quelldatenbank, TargetConnection=Zieldatenbank;
Dieser Befehl führt alle mit "prepare" angegebenen Vorgänge in der Reihenfolge aus in der diese angegeben wurden.
Bei SourceConnection die Quelldatenbankverbindungsname oder Quelldatenbankverbindungszeichenfolge angeben.
Bei TargetConnection die Zieldatenbankverbindungsname oder Zieldatenbankverbindungszeichenfolge angeben.
Beispiele für Verbindungszeichenfolgen für die Verschiedenen Datenbank Typen:
'POSTGRE:UserId=postgres;Password=manager;Server=localhost;Port=5432;'
'SQLITE:Filename=C:\Transfer\gruen.sqlite'
'ORACLE:Username=osnab;Password=avs;Service=orcl'
'SQLSERVER:Server=localhost;Database=mumpi;UserId=micha;Password=avs;'
Verbindungszeichenfolgen sind immer in einfache Anführungszeichen eingeschlossen. Achten Sie darauf das alle Parameter genau so geschrieben sind wie im Beispiel. Gross und Kleinschreibung beachten! Keine Leerzeichen!
Statt der Verbindungszeichenfolge kann, wenn im AppBuilder eine Datenbankverbindung für die Datenbank vorhanden ist, auch diese genutzt werden.
Beispiel:
datatransfer execute with SourceConnection=gruen, TargetConnection=stuttgart_gruen;
Datenbankverbindungen sind NICHT in Einfache Anführungszeichen eingeschlossen.
Wenn die Zieldatenbank eine MapEdit Datenstruktur hat, dann wird nach dem kopieren der Datensätze die FID Sequence "ME_NEXT_FID" jeweils auf die neue höchste FID angepasst.
Der Befehl "datatransfer execute" kann mehrfach ausgeführt werden, z.B. wenn die Daten von einer Datenbank in mehrere andere Datenbanken kopiert werden sollen.
datatransfer ShowLog;
Dieser Befehl öffnet das Verzeichnis "C:\Users\IhrUser\Documents\MapEdit\DataTransfer" und öffnet die Fehler Datei "*.error.txt".
Die Befehle "datatransfer prepare" und "datatransfer execute" können mit dem "Repeat" Befehl kombiniert werden. Dadurch kann man statt für jede einzelne Tabelle einen Befehl zu schreiben, die Tabellen Namen aus einer Hilfstabelle holen. Beachten Sie aber das der Select im FOR Abschnitt auf die aktuell Datenbank des SQL Abfrage Tools geht!
Beispiel:
Kopiere die Daten aller Feature Klassen Tabellen
REPEAT datatransfer prepare copy data to table $table_name using select table_name from ME_ALL_FEATURECLASSES;
Beispiel:
Kopiere die Daten aller Domain Tabellen
REPEAT datatransfer prepare copy data to table $table_name using select table_name from ME_TABLE where is_domain=1 and table_name not like 'ME_%'
Man kann mittels des "Repeat" Befehls auch Befehle auf mehrere Datenbanken anwenden wenn man Aktionen auf mehrere Datenbanken anwenden will.
Dazu muss man vorab die Datenbanknamen in eine Hilfstabelle der Datenbankverbindung schrieben mit der man beim ausführen verbunden ist.
Beispiel:
datatransfer StartNewLog;
datatransfer Clear;
datatransfer prepare execute sql in source using delete from STRASSEN;
REPEAT datatransfer execute with SourceConnection='SQLITE:Filename=C:\Transfer\TechnoAlpin\Plan\$dbname.sqlite',TargetConnection='POSTGRE:UserId=postgres;Password=manager;Database=$dbname;Server=localhost;Port=5432;' FOR select lower(dbname) as dbname from DATABASENAMES;
datatransfer ShowLog;
Das Beispiel führt für jede Datenbank in der Hilfstabelle "DATABASENAMES" ein "delete from STRASSEN" aus.
SQL Befehle in mehreren Datenbanken ausführen (BATCH)
Mit dem Befehl BATCH (Stapel) können Sie einen SQL Befehl in mehreren Datenbanken ausführen lassen. Dies kann unter anderem ein nützliches Werkzeug bei Verwendung der Variantenplannung sein.
Beispiel: Sie haben 5 Baum Datenbanken und wollen in allen 5 Datenbank diese drei SQL Befehle ausführen. z.B.:
Update BAUM set baum_zustand='ok' where baumart='unbekannt';
Update BAUM set baum_zustand='gut' where baumart='schlecht';
Delete from Baum where baum_type=33;
Um das zu tun müssen sie normalerweise jede Datenbank einzeln händisch öffnen und dann in jeder Datenbank den SQL Befehl ausführen oder sich ein Script zusammenstellen.
Der Befehl BATCH vereinfacht dieses Problem. Man gibt hier die SQL Befehle einmalig an und sagt dann in welchen Datenbanken diese ausgeführt werden sollen.
Für das obige Beispiel würde das folgendermaßen aussehen:
BATCH STARTNEWLOG;
BATCH CLEAR;
BATCH PREPARE Update BAUM set baum_zustand='ok' where baumart='unbekannt';
BATCH PREPARE Update BAUM set baum_zustand='gut' where baumart='schlecht';
BATCH PREPARE Delete from Baum where baum_type=33;
BATCH EXECUTE USING BAUM_LASVEGAS;
BATCH EXECUTE USING BAUM_DITZINGEN;
BATCH EXECUTE USING BAUM_STUTTGART;
BATCH EXECUTE USING 'SQLITE:Filename=C:\Transfer\Baum_Leonberg.sqlite';
BATCH SHOWLOG;
Erklärung der einzelnen Schritte:
BATCH STARTNEWLOG;
Dieser Befehl erzwingt das eine neue Log und Error Datei im Verzeichnis
"C:\Users\IhrUser\Documents\MapEdit\Batch" angelegt wird.
Wird dieser Befehl ausgelassen dann wird die zuletzt in der Sitzung verwendete Log Datei verwendet.
Das System legt hierbei zwei Dateien an. Eine Datei mit Namen *.log.txt in der alle Vorgänge protokolliert werden und eine Datei mit dem Namen *.error.txt in der alle Fehler protokolliert werden.
BATCH CLEAR;
Dieser Befehl sorgt dafür das alle "BATCH PREPARE" Befehle aus der Befehlsliste entfernt werden.
BATCH PREPARE Update BAUM set baum_zustand='ok' where baumart='unbekannt';
Der Befehl BATCH PREPARE fügt den SQL Befehl der Befehlsliste hinzu führt diesen jedoch noch nicht aus.
Hier können Standard SQL Befehle wie insert, update, delete, alter table, etc. angegeben werden. MapEdit Spezial Befehle werden zur Zeit hier nicht unterstützt, mit Aussnahme des REPAIR me_next_fid Befehls.
"Select * from" Befehle können hier mit Einschränkung auch angegeben werden. Sie dazu mehr weiter unten.
BATCH EXECUTE USING BAUM_LASVEGAS;
Der Befehl BATCH EXECUTE USING Datenbankverbindungsname führt alle Befehle der Befehlsliste in der angegebenen Datenbankverbindung aus.
Statt einem Datenbankverbindungsname kann auch eine Verbindungszeichenfolge verwendet werden. Details siehe Befehl "datatransfer" oben.
Wird ein Connection Router angegeben dann wird die Befehlsliste in allen Datenbankverbindungen des Routers ausgeführt.
BATCH SHOWLOG;
Dieser Befehl öffnet das Verzeichnis "C:\Users\IhrUser\Documents\MapEdit\Batch" und öffnet die Log und Fehler Dateien.
Ausführen von Prüfungen oder Ausgabe von Information
Wird bei "BATCH PREPARE" ein SELECT Statement angegeben, dann wird das Ergebnis des Select in die Fehlerdatei ausgegeben. Dies kann zum Beispiel für Prüfungen verwendet werden. Beachten Sie dass eine Ausgabe nur erfolgt wenn ein nicht NULL Wert vorhanden ist.
Das folgende Beispiel prüft ob die Sequence 'me_next_fid' vorhanden ist und gibt wenn nicht eine Meldung in die Fehlerdatei aus.
BATCH PREPARE SELECT case count(*) when 0 THEN 'Sequence me_next_fid is missing' end case FROM information_schema.sequences where sequence_name ='me_next_fid';
Das folgende Beispiel gibt die Anzahl Datensätze der Tabelle Baum aus.
BATCH PREPARE SELECT 'Tabelle BAUM hat ' || count(*) ||' Datensaetze ' from BAUM;
Variantenplanung
Bei der Variantenplanung kann es unter Umständen hunderte von Planungsdatenbanken geben. Damit man in dem Fall nicht alle Planungsdatenbank Namen händisch angeben muss gibt es den Befehl.
BATCH EXECUTE USING ALLPLANNINGCONNECTIONS OF Name der Bestands Datenbank;
Man gibt hier nur den Namen der Bestandsdatenbank an und das Programm ermittelt dann alle Planungsdatenbanken die zu dieser gehören. Das Programm ermittelt diese mittels der Tabelle ME_PLANNING_VARIATION der Bestandsdatenbank.
Das folgende Beispiel führt in allen Planungsdatenbanken der Bestandsdatenbank "BESTAND_001" einen SQL aus der prüft ob die Sequence me_next_fid vorhanden ist und gibt das Ergebnis aus.
Beispiel:
BATCH STARTNEWLOG;
BATCH CLEAR;
BATCH PREPARE SELECT case count(*) when 0 THEN 'Sequence me_next_fid is missing' end case FROM information_schema.sequences where sequence_name ='me_next_fid';
BATCH EXECUTE USING ALLPLANNINGCONNECTIONS OF BESTAND_001;
BATCH SHOWLOG;
Wird ein Connection Router anstelle der Bestandsdatenbank angegeben dann wird die Befehlsliste in allen Planungsdatenbanken aller im Router aufgeführten Bestands Datenbankverbindungen ausgeführt.
Beachten Sie das die Befehle hierbei nur in den Planungsdatenbanken ausgeführt werden und nicht in der Bestandsdatenbank selbst! Wenn Sie dies wollen müssen Sie eine weitere Zeile
BATCH EXECUTE USING BESTAND_001;
hinzufügen.
FID Sequenz reparieren
Ist nur für das MapEdit Datenmodel verfügbar.
Beispiel:
REPAIR ME_NEXT_FID;
Der Befehl prüft ob eine Sequenz mit dem Namen ME_NEXT_FID vorhanden ist und legt diese wenn nicht vorhanden an.
Außerdem wird die maximale FID aller Tabellen ermittelt. Ist diese maximale FID grösser als der Wert der Sequenz, dann wird die Sequenz auf den maqximalen FID Wert gesetzt/repariert.
Koordinatensystem Code (SRID/EPSG Code) ändern
Verfügbar ab Version 25.1.28
Ändert den SRID (EPSG Code) der Datenbank.
Bitte erstellen Sie vor dem Ändern der SRID ein Backup der Datenbank.
Diese Funktion ändert/transformiert keine Koordinaten. Nur der SRID/ESPG wird geändert.
Beispiel:
CHANGESRID Connection=elektro_pg_1, NewSrid=26911
Bitte beachten Sie, dass diese Aktion auch zu Fehlern führen kann. Je nach Datenbank müssen Indizes und/oder Views gelöscht und neu angelegt werden. Sollte während dieses Vorgangs ein Verbindungsabbruch geschehen oder der Vorgang manuell abgebrochen werden, wird die Datenbank anschließend unvollständige Indizes und fehlende Views aufweisen
Bitte beachten Sie, dass die SRID einer Tabelle in Postgres nicht editiert werden kann, solange eine View existiert, die die Geometriespalte der betroffenen Tabelle nutzt. Um die SRID dennoch zu editieren, muss die View vorab gelöscht und anschließend neu erstellt werden.
Statt einem Datenbankverbindungsnamen kann auch eine Verbindungszeichenfolge genutzt werden.
Beispiel
CHANGESRID Connection='POSTGRE:UserId=elektro_pg_1;Password=manager;Server=localhost;Port=5432;', NewSrid=26911
Weitere Beipiele zu Verbindungszeichenfolge finde Sie unter
"Datensätze von einer Datenbank in andere Datenbank kopieren"
https://help.mapedit.de/docs/dokumentation/MapEdit-AppBuilder/database-connections/Sql/QueryTool#datens%C3%A4tze-von-einer-datenbank-in-andere-datenbank-kopieren
Geometrie Transformieren
Transformiert alle Koordinaten einer Tabelle.
Beispiel:
TransformGeometry SourceEPSG=3421, TargetEPSG=26911, TableName=STREETS, Filter="";
TransformGeometry SourceEPSG=3421, TargetEPSG=26911, TableName=TREES, Filter="FID>11234 and COLOR=15";
| Parameter | Beschreibung |
|---|---|
| SourceEPSG | Quell Koordinatensystem |
| TargetEPSG | Ziel Koordinatensystem |
| TableName | Tabellenname |
| Filter | SQL Where Bedigung die die Datensätze einschränkt, muss in Doppelten Anführungszeichen stehen. |
- Die Funktion ändert nur die reinen Koordinaten, nicht den SRID/EPSG Code!
- Eine MapEdit/AutoCad Map Datenbank nur ein Koordinatensystem haben! d.h. das Ziel Koordinatensystem muss dem der Datenbank entsprechen damit Spatial Abfragen etc funktionieren.
- Die Einstellungen der Geometrie Metadaten Tabellen werden mit dieser Funktion nicht geändert!
- Die Funktion ignoriert das beim Geometrie Datensatz angegebene Koordinatensystem und nimmt fix das als Parameter angegebene Koordinatensystem (SourceEPSG)
Dies kann nachdem alle Tabellen transformiert wurden mit der Funktion "SRID" geschehen.
Siehe
https://help.mapedit.de/docs/next/dokumentation/MapEdit-AppBuilder/database-connections/structure/more#srid-%C3%A4ndern
Duplikate finden
Findet Datensätze in denen in einer oder mehreren Spalten die gleichen Werte stehen.
Beispiele:
FindDuplicates TableName="STRASSEN", DuplicateColumns="name";
FindDuplicates TableName="STRASSEN", KeyColumn="fid", DuplicateColumns="name", DisplayColumns="fid,name,geom", Filter="fid>0";
| Parameter | Beschreibung |
|---|---|
| TableName | Tabelle in der gesucht werden soll |
| KeyColumn | (optional bei Tabellen) Spalte die den Datensatz eindeutig identifiziert |
| DuplicateColumns | Liste der Spaltennamen die verglichen werden sollen |
| DisplayColumns | (optional) Spalten die in der Ausgabe angezeigt werden sollen |
| Filter | (optional) SQL Where Bedigung die die Datensätze einschränkt, muss in |
| IncludeFirst | (optional) Wenn Wert auf FALSE gesetzt wird dann wird der erste Datensatz der doppelten Datensätze nicht mit in das Ergebnis aufgenommen. (Default Wert ist TRUE) |
Wird der Befehl auf Views ausgeführt, dann muss die Spalte die bei "KeyColumn" angegeben wurde eindeutige Werte enthalten, ansonsten kommen falsche Ergebnisse.
Ob die Werte eindeutig sind können Sie so feststellen: In diesem Beispiel ist die KeyColumn die FID select count(fid) from viewname; select count(unique(fid)) from viewname;
Die Parameter Werte müssen zwingend in doppelten Anführungszeichen stehen sobald im Ausdruck ein Komma steht. Ansonsten können diese wahlweise entfallen.
Beispiel:
Die Ausgangstabelle ist eine Tabelle mit Strassennamen und sieht folgendermaßen aus:
| FID | NAME |
|---|---|
| 1 | Tropicana Way |
| 2 | String Mountain Road |
| 3 | Las Vegas Blvd |
| 4 | String Mountain Road |
| 5 | Carbondale Street |
| 6 | Ranch Road |
| 7 | Carbondale Street |
Man will nun alle Datensätze finden in denen doppelte Werte stehen. In diesem Fall kommt der NAME "String Mountain Road" und "Carbondale Street" mehrfach vor.
FindDuplicates TableName="STRASSEN", DuplicateColumns="NAME"
gibt folgendes Result aus:
| FID | NAME |
|---|---|
| 2 | String Mountain Road |
| 4 | String Mountain Road |
| 5 | Carbondale Street |
| 7 | Carbondale Street |
FindDuplicates TableName="STRASSEN", DuplicateColumns="NAME", IncludeFirst=False
gibt folgendes Result aus:
| FID | NAME |
|---|---|
| 4 | String Mountain Road |
| 7 | Carbondale Street |
In Postgres können hiermit auch doppelte Punkt Geometrien gesucht werden.
Diese bedingt jedoch dass die Geometrie auf alle Nachkommastellen gleich ist!
Bei anderen Geometrietypen als Punkt werden doppelte nur gefunden wenn die Reihenfolge der Knotenpunkte die gleiche ist.
Duplikate löschen
Löscht Datensätze in denen in einer oder mehreren Spalten die gleichen Werte stehen.
Beispiele:
DeleteDuplicates TableName="STRASSEN", DuplicateColumns="name";
DeleteDuplicates TableName="STRASSEN", KeyColumn="fid", DuplicateColumns="name", Filter="fid>0";
| Parameter | Beschreibung |
|---|---|
| TableName | Tabelle in der gesucht werden soll |
| KeyColumn | (optional) Spalte die den Datensatz eindeutig identifiziert |
| DuplicateColumns | Liste der Spaltennamen die verglichen werden sollen |
| Filter | (optional) SQL Where Bedigung die die Datensätze einschränkt, muss in |
Die Parameter Werte müssen zwingend in doppelten Anführungszeichen stehen sobald im Ausdruck ein Komma steht. Ansonsten können diese wahlweise entfallen.
Beispiel:
Die Ausgangstabelle ist eine Tabelle mit Strassennamen und sieht folgendermaßen aus:
| FID | NAME |
|---|---|
| 1 | Tropicana Way |
| 2 | String Mountain Road |
| 3 | Las Vegas Blvd |
| 4 | String Mountain Road |
| 5 | Carbondale Street |
| 6 | Ranch Road |
| 7 | Carbondale Street |
Man will nun alle Datensätze löschen in denen doppelte Werte stehen. In diesem Fall kommt der NAME "String Mountain Road" und "Carbondale Street" mehrfach vor.
DeleteDuplicates TableName="STRASSEN", DuplicateColumns="NAME"
Dieser Befehl löscht die Datensätze:
| FID | NAME |
|---|---|
| 4 | String Mountain Road |
| 7 | Carbondale Street |
In Postgres können hiermit auch doppelte Punkt Geometrien gelöscht werden.
Diese bedingt jedoch dass die Geometrie auf alle Nachkommastellen gleich ist!
Bei anderen Geometrietypen als Punkt werden doppelte nur gefunden wenn die Reihenfolge der Knotenpunkte die gleiche ist.
Mit FindDuplicates und setzen des Parameters "IncludeFirst=False" können sie vor dem Löschen vorab prüfen welche Datensätze gelöscht werden!
Der Befehl löst keinen Feature Rules aus
Linienzug aufbrechen
Wandelt Linienzüge in einzelne Linien um und speichert diese in einer anderen Tabelle.
Ab Version 25.2.28 können auch Flächen in einzelne Linien umgewandelt werden.
Beispiel:
CreateLineSegments SourceTableName=LINE1, TargetTableName=LINE2,
TargetParentColumnName=FID_PARENT, Filter="";
| Parameter | Beschreibung |
|---|---|
| SourceTableName | Quell Tabelle (Flächen Tabelle oder Linienzug Tabelle) |
| TargetTableName | Ziel Tabelle (Linien Tabelle) |
| TargetParentColumnName | Feld in der Zieltabelle in der die FID der Quelltabelle geschrieben werden soll. (Damit ist hinterher eine Verknüpfung der beiden Tabellen verfügbar) |
| Filter | SQL Where Bedigung die die Datensätze einschränkt, muss in doppelten Anführungszeichen stehen. |
Mittelpunkte aus Flächen erzeugen
Ab Version 25.2.28
Erzeugt Mittelpunkte aus Flächen/Linienzüge und speichert diese in einer anderen Tabelle.
Beispiel:
CreateCenterPoints SourceTableName=AREA1, TargetTableName=LINE2,
TargetParentColumnName=FID_PARENT, Filter="";
| Parameter | Beschreibung |
|---|---|
| SourceTableName | Quell Tabelle (Flächen Tabelle oder Linien Tabelle) |
| TargetTableName | Ziel Tabelle (Punkt Tabelle) |
| TargetParentColumnName | Feld in der Zieltabelle in der die FID der Quelltabelle geschrieben werden soll. (Damit ist hinterher eine Verknüpfung der beiden Tabellen verfügbar) |
| Filter | SQL Where Bedigung die die Datensätze einschränkt, muss in doppelten Anführungszeichen stehen. |
Punkte aus Linien erzeugen
Liest die Stützpunkte einer Linie/Fläche und speichert die Punkte in einer anderen Tabelle ab.
Beispiel:
CreateNodes SourceTableName=LINE_TABLE, TargetTableName=POINT_TABLE, TargetParentColumnName=FID_PARENT, Filter="fid>0";
| Parameter | Beschreibung |
|---|---|
| SourceTableName | Quell Tabelle (Linie oder Fläche) |
| TargetTableName | Ziel Tabelle (Punkte) |
| TargetParentColumnName | Feld in der Zieltabelle in der die FID der Quelltabelle geschrieben werden soll. (Damit ist hinterher eine Verknüpfung der beiden Tabellen verfügbar) |
| Filter | SQL Where Bedigung die die Datensätze einschränkt, muss in Doppelten Anführungszeichen stehen. |
Geometrie als Karte anzeigen
Mit dem Befehl "MAP select" können Geometrien graphisch als Karte angezeigt werden.
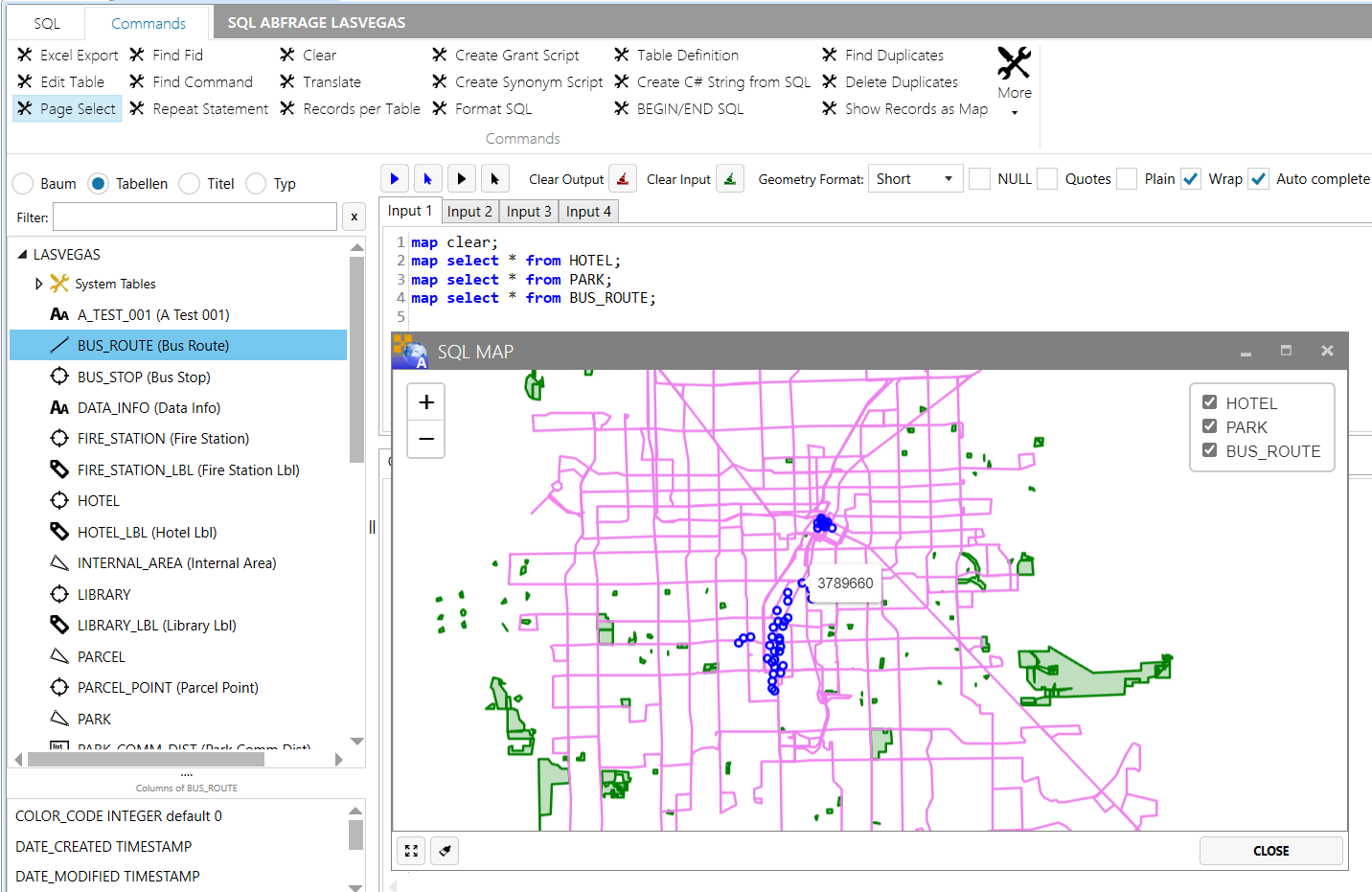
Um die Karte zu leeren benutzen Sie:
MAP clear
Um neue Feature der Karte hinzuzufügen benutzten Sie
MAP select * from streets where x=y
Beispiele:
MAP select * from streets where fid=177;
MAP select * from park;
Halten Sie die Anzahl der Datensätze klein. Kleiner 10000 Datensätze.
Wenn Sie der Karte zu viele Feature hinzufügen wird die Karte sehr sehr langsam
werden und der RAM Speicherverbrauch ihres Computer steigen.
Je Layer können maximal 10000 Datensätze angezeigt werden, weitere Datensätze werden ignoriert
und es erscheint eine Meldung im SQL Ausgabefenster.
Datenstruktur vergleichen - CompareSchema
Ab Version 25.1.37
Mit dem Befehl "CompareSchema" kann das Datenbank Schema zweier Datenbanken verglichen werden.
Beispiele
compareSchema SourceConnection=WASSER_11, TargetConnection=WASSER_11_ME
compareSchema TargetConnection=WASSER_11_ME
compareSchema TargetConnection='POSTGRE:UserId=elektro_pg_1;Password=manager;Server=localhost;Port=5432;'
Wird SourceConnection weggelassen wird die aktuelle Datenbankverbindung verwendet.
Die Funktion vergleicht folgendes:
- Sind alle Tabellen vorhanden
- Sind alle Indexe vorhanden (hierbei wird der Indexname nicht verglichen, nur die Definition)
- Sind alle Spalten vorhanden
- Haben die Spalten die gleiche Definition (Also Datentyp, Name etc)
- Ist der Type der Tabelle gleich. Punkt, Linie, Attribute etc
- Sind alle Views vorhanden
- Ist die View Definition die gleiche
Andere Dinge werden nicht verglichen!!
Datensätze vergleichen - Compare
Mit dem Befehl "Compare" kann der Inhalt von zwei Tabellen verglichen werden. Datensätze mit dem jeweils gleichen Schlüssel (Key) werden verglichen. Beispiel FID, ID, NAME etc.
Die Unterschiede werden ausgegeben. Der Befehl vergleicht keine Views/Synonyme. Die Tabellen können in unterschiedlichen Datenbanken liegen.
Beide Tabellen müssen einen eindeutige Primärschlüssel (z.B. FID oder ID) haben.
Beispiel/Syntax
compare SourceConnection="WASSER_11", TargetConnection="WASSER_11_ME", SourceQuery="select * from wa_string", TargetQuery="select * from wa_string", SOURCEKEY="FID", TARGETKEY="FID"
SourceConnection/TargetConnection: Name der Datenbankverbindung
Wird TargetQuery weggelassen dann wird SourceQuery für TargetQuery verwendet.
Wird SourceConnection weggelassen dann wird die aktuelle Verbindung als SourceConnection verwendet.
Werden die Parameter SourceQuery/TargetQuery/SourceKey/TargetKey weggelassen dann wird die ganze Datenbank verglichen.
SourceQuery/TargetQuery können einen Tabellennamen oder einen Select enthalten.
Beispiele:
compare SourceQuery="bus_route", TargetConnection="LASVEGAS_ORA";
compare SourceQuery="bus_route", SourceKey="NAME", TargetConnection="LASVEGAS_ORA";
compare SourceQuery="bus_stop", TargetConnection="LASVEGAS_ORA";
compare SourceQuery="select * from wa_string order by fid", SourceKey="FID", TargetConnection="WASSER_11_ME";
compare TargetConnection="WASSER_11_ME";
Es werden nur Spalten mit gleichem Namen verglichen. In "COLUMN NAME DIFF" werden alle Spaltennamen aufgelistet die in den Tabellen verschieden sind.
SQL Export
Gibt die Daten als SQL Insert Anweisungen aus.
Syntax:
EXPORT select * from mytable
EXPORT select * from mytable FOR POSTGRE
EXPORT select * from mytable FOR ORACLE
EXPORT select * from mytable FOR SQLITE
Optional kann der Ziel Datenbanktyp angegeben werden wenn dieser nicht dem aktuellen Datenbank Typ entspricht. Dadurch wird einem der Zieldatenbank passender SQL erzeugt. Das ist vorallem für das Geometrie Format, Datum und Zeilenumbrüche wichtig. Zwischen "FOR" und dem Datenbanktyp muss genau ein Leerzeichen stehen.
Zur Ausgabe in eine Datei
Syntax:
EXPORT select * from mytable TO 'c:\Test.sql'
EXPORT select * from mytable TO 'c:\Test.sql' FOR POSTGRE
Wenn die Tabelle sehr viele Datensätze hat kann der Vorgang einige Zeit dauern. Sie sollte dann die Ausgabe in eine Datei wählen da der Editor bei großen Datenmengen sehr langsam wird.
Excel Export
Exportiert die Daten einer Abfrage in eine Excel Datei
Syntax:
EXPORT select * from mytable TO 'c:\Test.xlsx'
Der Ziel Dateiname muss in '' geschrieben werden.
SpeedTest (Geschwindigkeits Test)
Mit dem Befehl SPEEDTEST kann getestet und verglichen werden wie lange Abfragen auf unterschiedlichen Datenbanken benötigen.
Hiermit kann man testen wie lange Abfragen bei verschiedenen Datenbank Typen (Oracle/Postgre etc) dauern.
Der Test führt einen SQL auf die gegebene Tabelle (Parameter tablename) mehrfach mit verschiedener anzahl an Datensätzen aus und protokolliert die Ausführungszeiten.
Bei Parameter Connection1,Connection2, etc werden die zu testenden Datenbankverbindungen angegeben. Es können bis zu maximal 5 Datenbanken verglichen werden.
Dieser Test kann zum Beispiel auch für Geschwindigkeitsvergleiche zwischen MapEdit Core (neu, future Releases) und MapEdit Server WFC (classic) ausgeführt werden.
Beispiel
SPEEDTEST tablename='STREET', Connection1=LASVEGAS, Connection2=LASVEGAS_ORA, Connection3=LASVEGAS_SQLITE
SQL Monitor
Hier sieht man alle SQLs die gerade auf der Datenbank laufen. Hier sieht man lang laufende SQL's und kann diese abbrechen (gleich wie im pg admin)
Diese Funktion steht zur Zeit nur für Postgres zur Verfügung.
SQL Error Monitor
Wenn MapEdit Client/Professional SQLs ausführt die z.B. wegen Syntaxfehlern, fehlenden Views/Tabellen etc fehlschlagen dann werden diese im Log von MapEdit Client/Professional angezeigt.
Fehler die vom AppBuilder erzeugt werden, finden Sie im Log vom AppBuilder.
Serverseitige Fehler finden sie außerdem in der Logdatei auf dem MapEdit Server unter C:\inetpub\wwwroot\MumGeoData\Log
Für Oracle steht außerdem ein "SQL Error Monitor" zur Verfügung. Dieser zeigt Oracle Fehler an.
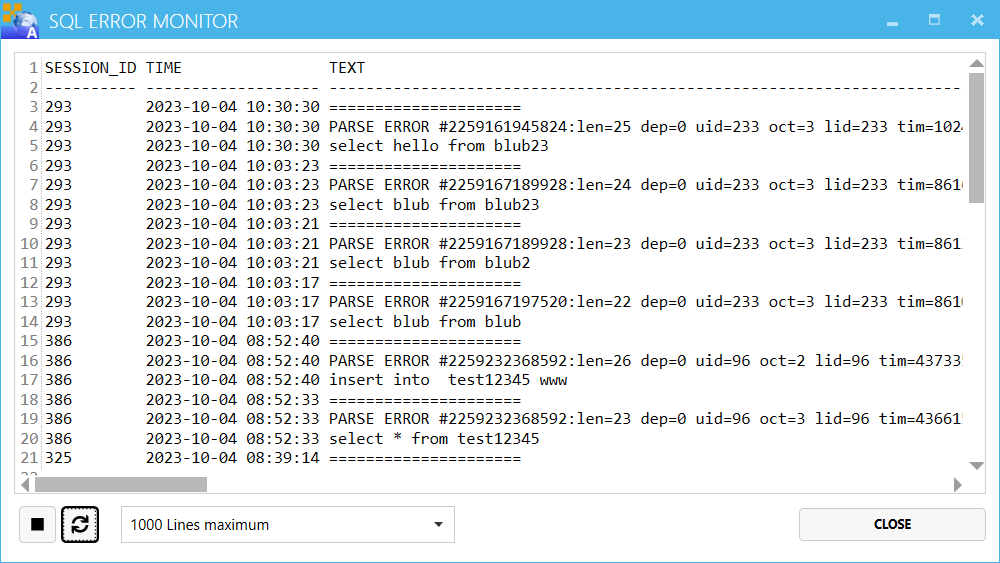
Loggen Sie dazu mit einem User ein der System Berechtigungen hat (wie z.B. SYSTEM).
Der User muss Leserechte auf den View V$DIAG_TRACE_FILE_CONTENTS haben, ansonsten wird der SQL Monitor nicht funktionieren.
Drücken Sie den Start Knopf, starten sie das Programm das SQL Fehler erzeugt. Drücken Sie den Stop Knopf. Danach werden die Fehler Informationen aus den Oracle Trace Dateien gelesen und angezeigt.
Beachten Sie das diese Monitoring ggf die Geschwindiogkeit von Oracle heruntersetzt!
Beenden Sie deswegen dieses immer. Sie werden beim Schließen des Dialog ggf auch darauf hingewiesen.
Diese Funktion steht zur Zeit nur für Oracle zur Verfügung. Im Gegensatz zum SQL Fehler Spion im Map/Topobase SQLSheet muss diese Funktion nicht auf der Maschine ausgeführt werden auf der Oracle ausgeführt wird.
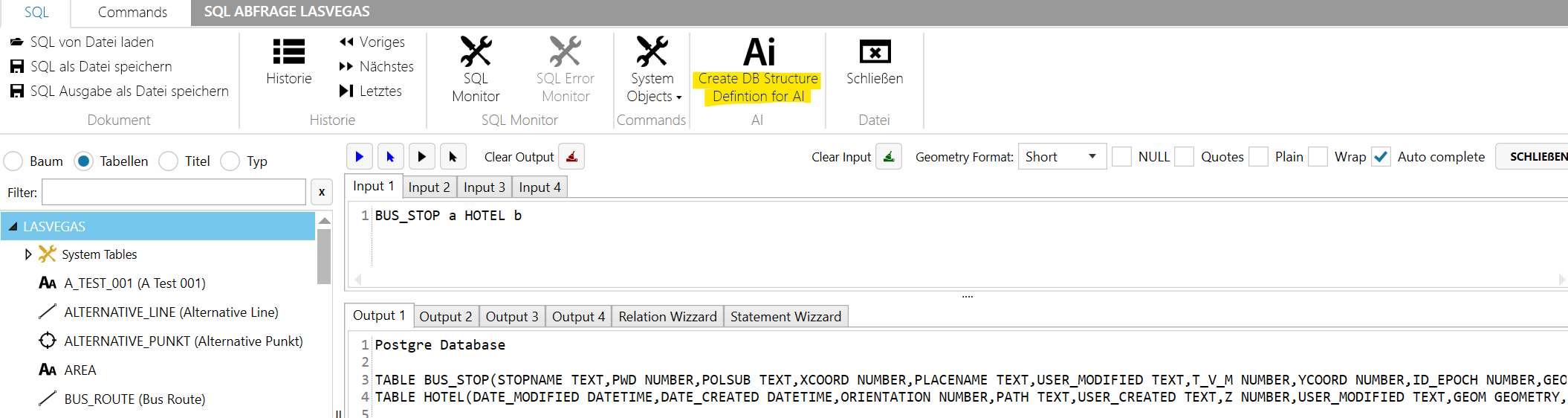
Datenstruktur Informationen für AI Abfragen erzeugen (Create DB Structure for AI)
Hiermit kann die Tabellenstuktur und Relationen der Tabellen als Text ausgegeben werden.
Diese Informationen können dann AI Werkzeugen, wie z.B. Microsoft Copilot, DuckDuckGo AI etc. gefüttert werden.
Damit können Sie dann via AI, Sqls erzeugen und das AI kennt ihre genauen Datenstruktur und erzeugt SQLs die genau auf Ihre Datenstruktur passen.
Beachten Sie das bei vielen AI Online Werkzeugen die Länge des Textes der eingegeben werden kann begrenzt ist, z.B. 10240 Zeichen bei Copilot AI. Für längere Texte kann man deswegen bei machen AIs den Text als Datei hochladen.
Es ist deswegen, um die Datenmenge klein zu halten ratsam nur Informationen zu den Tabellen die benötigt werden zu erzeugen.
Es gibt deswegen zwei Vorgehen:
Vorgehen für Einzeltabellen
- Tippen Sie in das Eingabfeld die benötigten Tabellennamen ein und drücken dann den Knopf "Create DB Structure for AI".
Bzw. wenn im Eingabefeld ein SQL steht nimmt das Programm alle Tabellen die in dem SQL beteiligt sind.
Vorgehen wenn Sie alle Tabellen der Datenbank wollen
- Drücken Sie Knopf "Create DB Structure for AI".
- Aktivieren Sie die Option "Full DB"
Es stehen beim erzeugen diverse Optionen zur Verfügung:
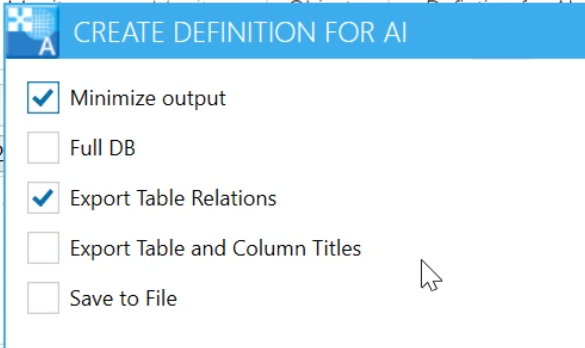
- Minimize output
Erzeugt wenn eingeschaltet nur die Spaltennamen und verkürztem Datentyp, diese ist für SQLs im Nornmalfall ausreichend.
Erzeugt wenn ausgeschaltet die Spaltennamen mit kompleten Datentyp, default werten etc.
Wozu ist "minimize output" gut?
Bei vielen AIs ist die länger beschränkt, z.B. 10240 Zeichen bei Copilot AI. D.h. wenn die Länge der Datenstruktur Information zu lang wird muss man diese via Datei hochladen oder in kleinere Blöcke aufteilen. Um das zu verhindern gibt es "minimize output", dadurch werden weniger Zeichen erzeugt. Bei AI's die nicht kostenlos sind wird außerdem nach Token (Wort) Anzahl bezahlt, d.h. je mehr Informationen gesendet werden desto teurer wird es.
-
Full DB
Wenn eigenschaltet werden alle Tabellen und Views der Datenbank ausgegeben.
Ansonsten nur die im Eingabefeld angegebenen Tabellen. -
Export Table relations Exportiert die Relationen zwischen den Tabellen.
-
Export Table and Column Titles Exportiert auch die Titel der Spalten und Tabellen.
-
Save to File Speichert die Ausgabe als Datei
Vorgehen:
-
Tippen Sie die Namen der beteiligten Tabellen in das Eingabefeld
-
Drücken Sie den Knopf "Create DB Structure for AI"
-
Drücken Sie OK. Das Ergebnis wird in die Zwischenablage kopiert.
-
Öffnen Sie ihr Ai Programm, z.B. Microsoft Copilot
-
Fügen die den Text aus der Zwischenablage in das AI Programm ein und drücken Sie ENTER. Damit kennt das AI ihre Datenstruktur.
-
Nun können Sie dem Ai sagen was der SQL den Sie erstellen wollen machen soll.
Beispiel: "Für jedes Hotel finde den Namen der nächst gelegensten Bushaltestelle und die Distanz" -
Das Ergebnis SQL können Sie dann im AppBuilder ausführen.
Wenn der SQL sich nicht ausführen lässt, dann geben Sie dem AI die Fehlermeldung oder sagen sie dem AI "Funktioniert nicht" damit kann das AI den Fehler den es selbst gemacht hat korrigieren.
Ja, das klingt komisch, ist aber so, die Intelligenz ist doch halt künstlich ;-) -
Sollange Sie das AI Programm nicht schließen kennt das AI ihre Datenstruktur und Sie können mit dieser arbeiten.
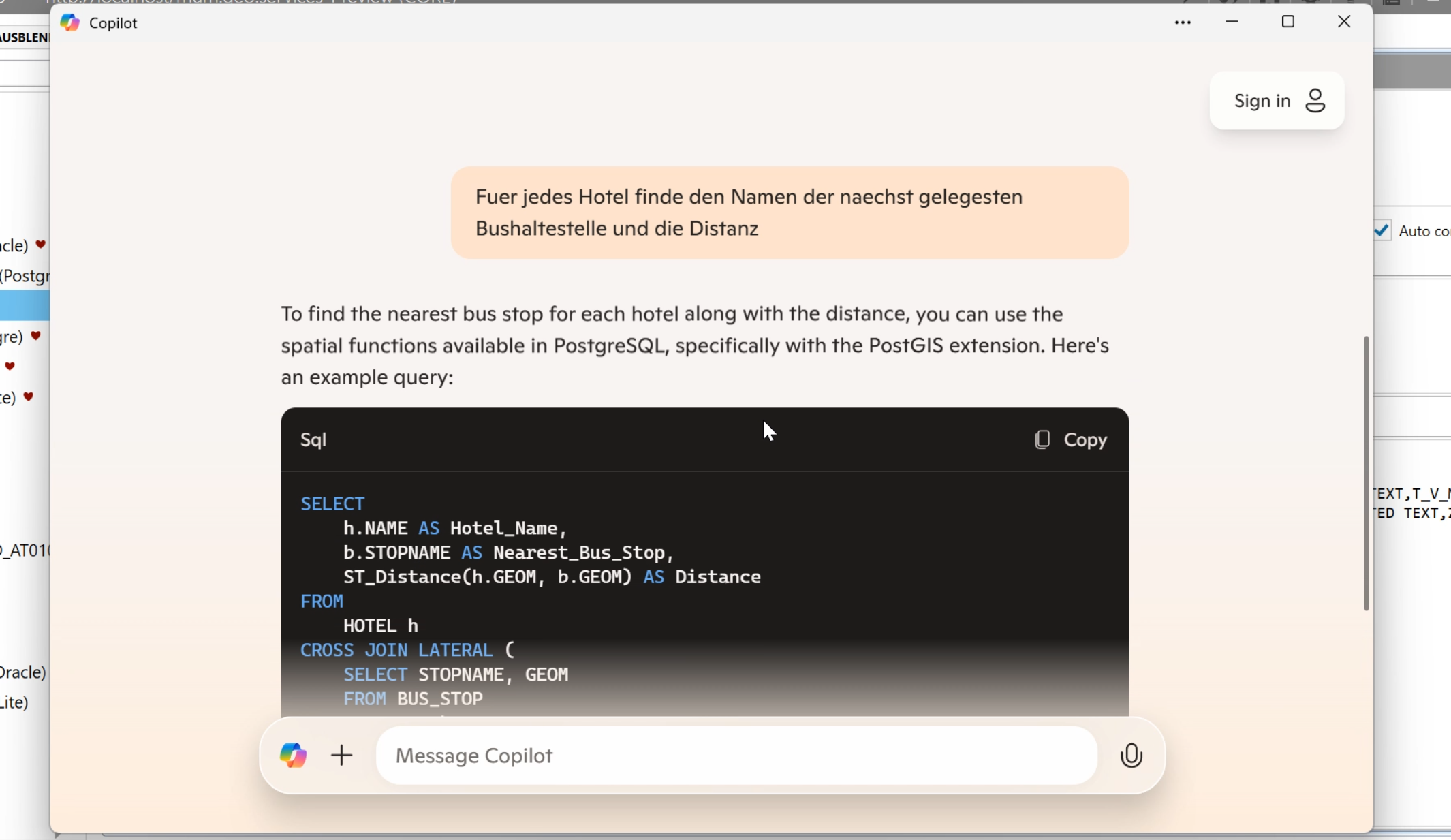
Fragen Sie vor Benutzung von AI Ihren Datenschutzbeauftragen!
Das AI Programm (nicht der AppBuilder) kann ggf ihre Daten für andere Zwecke verwenden!
Wenn die Datenstruktur zu gross wird laden Sie diese als Datei im AI hoch.
Wenn Das AI keine hochlade Funktion hat müssen Sie kleinere Abschnitte nacheinander eingeben und senden.
Micrososft Copilot hat eine Datei Hochlade Funktion.
Links zu AI Webseiten
Microsoft Copilot Ai
https://copilot.microsoft.com/
DuckDuckGO Ai (priorisiert Privatsphäre/Datenschutz)
https://duckduckgo.com/aichat
Es gibt natürlich viele mehr.....
Lang laufende SQL Befehle
Bei SQL Updates mit einer längeren Laufzeit kann es im AppBuilder zu folgender Fehlermeldung kommen:
SQL> update el_segment_duct a set fid_duct = ......
Der Objektverweis wurde nicht auf eine Objektinstanz festgelegt.
Die eigentliche Meldung ist die folgende:
pgsql.NpgsqlException
HResult=0x80004005
Message=Exception while reading from stream
TimeoutException: Timeout during reading attempt
D.h. der Postgres Provider steigt aus wegen einem Timeout.
Die default Postgres Einstellung ist so, dass es bei allen Befehlen (select, insert, update, delete usw.) 30 Sekunden wartet. Man kann diesen Defaultwert bei der Datenbankverbindung verändern. Ab Release 22.1.73 ist der Timeout nun auf 1 Tag gesetzt. "Command Timeout=86400" 86400 Sekunden = 24 Stunden
MapEdit AppBuilder (MapEdit Desktop/Professional) bleibt so lange stehen (und ist eingefroren) bis das Kommando durch ist. Auch wenn man den AppBuilder abschiesst läuft das Koammando dann weiterhin auf der Datenbank !!, auch wenn es 14 Tage dauert. Außer man fährt die Datenbank runter oder schiesst den SQL ab (was man im PGAdmin im Dashboard bei Server activities machen kann)
Ab Release 22.1 ist ein Wartefenster eingebaut mit einem Abbrechen Knopf. Mit diesem kann man das dann abbrechen.
Der Abbrechen Knopf den es bei Selects SQL bereits in alten Version gibt, bricht nur den Vorgang für den Client ab, wenn der sql bereits angefangen hat Werte zurück zu liefern.
Ab Release 22.1.73 gibt es nun einen Abbrechen Knopf bei (Updates/insert/delete und selects.)
Dückt man "Abbrechen" dann wird die clientseitige Abfrage abgebrochen und man kann das Programm weiter benutzen.
Bei Postgres wird zudem versucht die serverseitige Abfrage auch abzubrechen. Wenn das nicht gelingt bekommt man eine Meldung dass man diese mit dem SQL Monitor beenden muss. Es gibt im SQL Query einen neuen Knopf "SQL Monitor"
Hier sieht man alle SQLs die gerade auf der Datenbank laufen. Hier sieht man auch lang laufende SQL's und kann diese abbrechen (gleich wie im pg admin)
Macht man das nicht, dann belasten diese SQL's die Datenbank bzw laufen die SQL's so lange bis sie durch sind. Bei Oracle und SQLite ist diese Funktion des serverseitigen Abbrechens noch nicht eingebaut. Hier muss man mit dem SQL Sheet ggf die Session beenden.
Verwendung Datenbank unabhängiger SQL's für Views
Verwendung Datenbank unabhängiger SQL's für Views für Datenmodell Templates und Ora2SQLite Export
Beim Anlegen von Views über das Userinterface wird nun bei allen MapEdit Datenbanken in der Tabelle ME_VIEW der eingegebene SQL abgespeichert. Somit ist immer der Original SQL vorhanden. Der Grund dafür ist dass man damit für die Datenbank Vorlagen und den Ora2SQLite / Postgre2SQLite Export funktionierende Views anlegen kann.
Man muss wenn man das ganze Datenbank unabhängig haben will für die View SQL's die Oracle Syntax benutzen.
Das Ganze funktioniert nur für MapEdit Datenmodelle (ME_VIEW) und nicht für Map3D Fachschalen bzw. View Definitionen. In Map3D muss man mit den Post/Pre Skripten arbeiten oder keine Live-Views beim Export nach SQLite verwenden.